Introduction
The entire aim of optimization is to minimize the cost function. We will learn more about optimization in the later sections of the paper.
Batch Gradient Descent
Here we sum up all examples on every iteration while performing the updates for the weight or parameters. So for every update in weights, we need to sum over all examples. The weights and bias get updated based on gradient and learning rate(n).
Mainly advantages when there is a straight trajectory towards minimum and it has an unbiased estimate of gradients and fixed learning rate during training. Disadvantageous when we use vector implementation because we have to go over all the training set again and again. Learning happens when we go through all data even when some examples are reductant and with no contribution to the updating.
Stochastic Gradient Descent
Here unlike Branch Gradient Descent, we update the parameters on each example so learning happens on every example. So it converges more quickly than Batch Gradient Descent because weights update more frequently. Here, lots of oscillations take place which causes the updates with higher variance. These noisy updates help in finding new and better local minima. Due to frequent fluctuations, it will keep overshooting near to the desired exact minima.
Let us understand the gradient descent using examples.
Example 1
Will get to know: How will we reach to min-cost point.
Let’s take a cost function is f(x) and gradient df(x) given below
Our aim is to find the minimum cost. So let’s differentiate and equal to 0. The derivative is 2x+1. So the minimum occurs at x = -0.5. Let's understand this using below graphs. X range is taken from -3 to 3.
We can plot the curve and the derivative. Here we already know that the double derivative is positive. Now using gradient descent we can run so minimum it 500 times and if it reaches the minimum before 50 times, it will stop.
We can see the below figures how the points are traveling towards the minimum cost, as we started at x=-1/2 we get the minimum cost. As we started at x=3 and the learning rate was o and we asked for precision of 0.0001. In the last figure, we can see the close-up view of gradient descent.
Example 2
Will get to know: What happens if more than one minima.
Will get to know: Is starting point important ?.
Will get to know: Does learning rate have a role?.
Will get to know: Limitation of Gradient Descent.
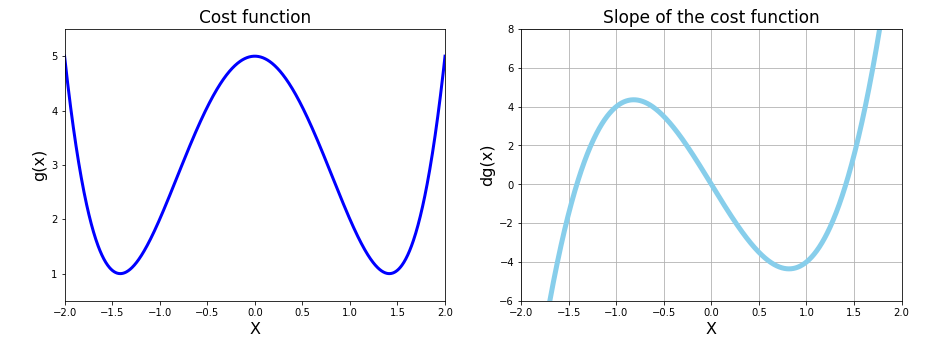
Let’s take a cost function is f(x) and gradient df(x) given below.
Our aim is to find the minimum cost. Let’s understand this using the below graphs. X range is taken from -2 to 2.
As we can see from the above figure we have two minima for the cost function. The slope of the cost function is zero at 3 points.
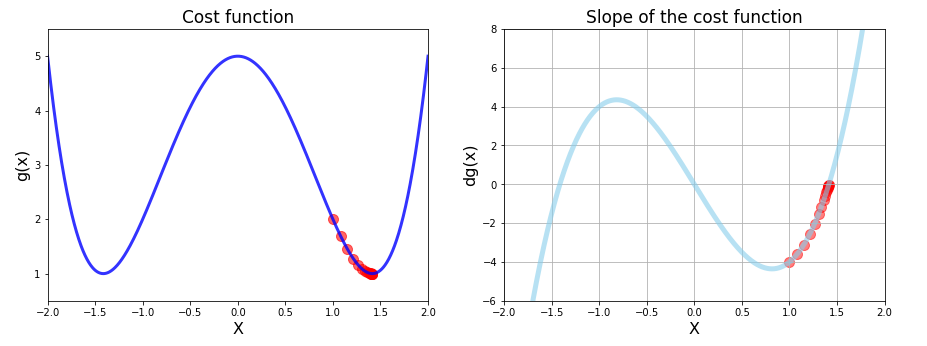
Is starting point important for gradient descendant?
Yes. The below graphs show that we converge to different minima based on the starting position. Now lets start at x = 1. We can see that we converged to the right minima.
Now let’s start at x = -1. We can see that we converged to left minima.
By the above figures, we can clearly state that the initial position we start determines the minima we converge. When we carefully see the above we see that the slope is zero at 3 points. When we start at X=0 then we see that we stop at the first iteration as the slope at X=0 is 0 but actually, it is not the minima.
Another limitation can be that if two minima are present and when the initial point is on the right side of local maxima and the global minima is not discovered.
Is learning rate important for gradient descendant?
I have made a picture to explain the learning rate effect on the Gradient Descent approach. The image explains what happens for different learning rates.
The pink line is of highest learning rate and green is the lowest learning rate and blue is the in-between the pink and green learning rates. From the below graph the high learning rate converges fast while the lower learning rate converges very slowly.
Gradient Descent with Neural Network














Comments
Post a Comment