Loss Functions Part - 1
Introduction
Loss Functions
Why we need Loss Functions?
Is Cost Function the same as the Loss function?
Do we use the same loss functions for all datasets?
Before we think of loss function, we need to identify what is the problem, we are solving is it regression or classification. In classification, we can use loss functions like Cross entropy, Hinge loss. In regression, we use SME, MAE, and Huber.
Are all loss functions Convex?
No. See the below image.

Why not use the same loss functions for Regression & Classification?
In classification for a penalty, we need to know the confidence by which the model predicts. It means, if the model predicted the wrong result with high confidence then it should be penalized more. In regression, we only see the difference between the predicted value and the actual value.
Derivation of Squared loss for Regression
A common choice of the loss function in regression problems is the squared loss. Now the process is choosing a specific estimate y(x) of the value of t for each input x. Suppose that in doing so, we incur a loss L(t, y(x)). The average, or expected, the loss is then given by E[L]. Our aim is to find E[L].


The optimal least square predictor is given by conditional mean and another term is intrinsic variability of target data. Now let’s see some of the loss functions for regression problems.
Mean Square Error (MSE)
Mean Square error is the most commonly used regression loss function.MSE is the sum of squared distances between our real target value and predicted value.
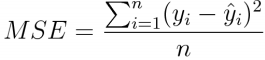
It overcomes the problem of above axis and below axis distance subtraction as now all values are positive. It doesn’t consider the direction it only concentrates on the average magnitude. As for the reason of squaring, predicted values which are far away from actual values are penalized heavily in comparison to less deviated prediction values. This property makes the MSE less robust to outliers. Therefore, it should not be used in our data is prone to many outliers. Observe the shape of MSE in the below figure.

A quadratic function only has a global minimum. As there are no local minima we will never get stuck in one. Hence, it is always guaranteed that Gradient Descent will converge to the global minimum (if it converges). MSE is equal to the sum of variance and bias squared. Below is the proof. By minimizing the MSE we can estimate the best fit line equation. First, let’s see the derivation.



Mean Absolute Error (MAE)
Mean absolute error is another loss function used for regression problems. MAE is the sum of differences between our target and predicted values with modules function.

So it doesn’t consider the direction of the error. As the difference is not squared it is more robust to outliers than MSE. But when we minimize MAE the prediction would be the median of the training dataset.
MAE Vs MSE
The predictions from the model with MAE loss are less affected by the outliers and noise whereas the predictions with MSE loss function are slightly biased due to the squared error. So people came up with RMSE which is just the square root of MSE. But the model with RMSE is adjusted for that small number of outliers which again reduces the performance. But we can’t come to a conclusion that always we will be using MAE because its derivatives are not continuous so inefficient to find the solution while using MSE we can find its derivative and equal to 0 to find the optimal solution. So if data has many outliers then use MAE as it is more robust than MSE for outliers.
Huber Loss
Huber loss is the combination of better points in MSE and MAE. Huber Loss is differentiable at 0 and less sensitive to outliers than MSE. It’s basically an absolute error, which becomes quadratic when an error is small. Huber loss approximates to MSE when δ ~ 0 and MAE when δ ~ ∞. But Huber loss also has a problem which is we need to train hyperparameter delta iteratively.
Comparison among the Loss Functions used for Regression
The thumb can be that when there are not many outliers we use MSE as our error function. The below is the graph showing all the above-discussed error functions together.



Comments
Post a Comment