Human Verification Using MNIST Dataset (with Code)
Introduction
In this paper, we will classify the handwritten digits using a multilayer neural network. We will use this classification to build the human verification system as we ask humans to write a 3-digit number and check if written correctly and validate the number entered by the user. As they are many ways to write some digits and they can be written anywhere in the box we use open CV to get the perfect size image and use ML to predict the number and their using JavaScript we verify the number. For the prediction, we are using a 3 hidden layer neural network. In the MNIST dataset, we get a 28*28 size image dataset in which each is surrounded by 4 pixels in every direction. We have achieved a 97.23% success rate of the classification of digits from the MNIST dataset.
MNIST data consists of 70,000 handwritten digit images. We will follow the steps from preprocessing to predicting the digit. We will start by understanding how an image will be understood by a computer.
We convert the image into an array of integers. We can express every single pixel of an image using 3 numbers there are red blue and green. But the MNIST data images are grayscale so we have only two channels there are white and black. So if an array element value is 255 which means the pixel is white while the value 0 represents black. The others values between 0 and 255 represent grey colors.

Figure:- First 16 digits of MNIST data set with labels.
Now let us see the distribution between the digits in the MNISTS dataset. Below is the table of frequency and donut chart of the distribution (70,000 images).

A machine learns better when the data is range 0 to 1 rather than 0 to 255 so for normalizing we use min-max normalization which in this case leads to the division of every array element by 255. As in normal life, we can write a digit in various ways so it will be hard to predict the digit. We need to split the data of 60,000 images into training, testing, and validation sets. I train our model with 50,000 images and for validation, we use 10,000 images and the remaining 10000 images for testing. Here validation sample helps us to select the best model and choose the constraints.

Table: The table shows the distribution of the MNIST dataset of 70.000 handwritten images.
The main parts of cleaning and pre-processing data are already done by the Modified National Institute of Standards and Technology. The images are sizes 28*28 but the digit will be only 20*20 size so the image is placed in the center and there is 4px padding on all 4 sides. Let us see the distribution of the digits in the test data set. The frequency of the digit 9 is the most which mean there are many handwritten 9 digits in the test data set.

Table: The above table shows us the distribution of the digits in the test set.
This is a 3-hidden layer neural network along with the input and output layer. Now, this is called multi-level perceptron. We can calculate the weights associated between every two neurons with the help of backpropagation to get better results All the layers use the Relu as activation function except the last layer which is SoftMax as we need to do the classification so we want to get probabilities in the last step to determine the highest probability as the predicted digit.

Figure: The complete diagram of the multilayer layer perceptron created by me.
We are not using Keras for the implementation of classification because we need to see the loss/cost functions using tensorboard for each of the epochs. We can get the best values of learning rate and several epochs by seeing the loss function from the tensorboard.
Accuracy Analysis

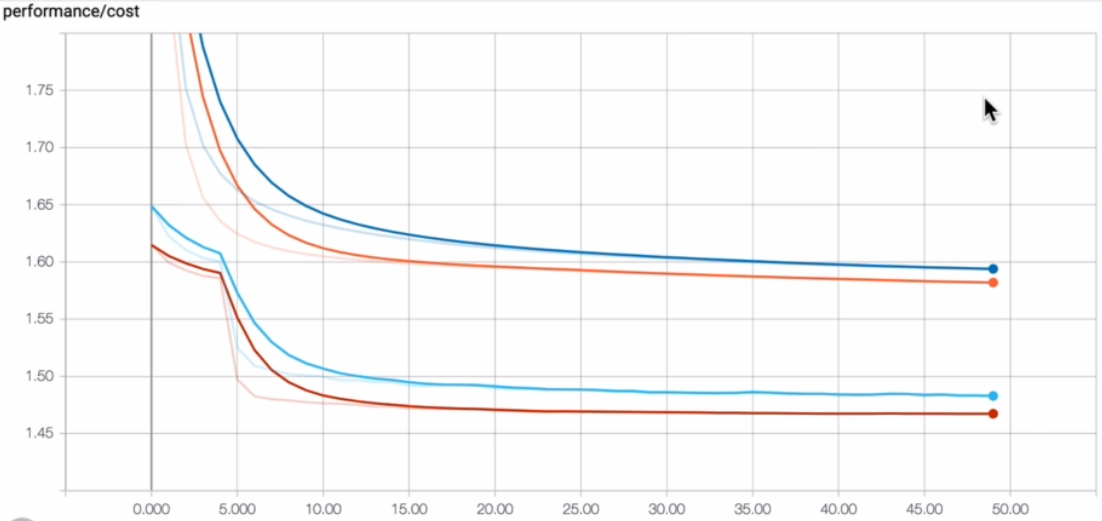
Figure: The figure shows the cost function of different epochs with 0.001,0.0001 learning rates for train and validates sets.
Overall we can see the cost function decreases with more epochs and the accuracy increases with the number of epochs. We can see a huge increase in accuracy and a huge decrease in cost function when the learning rate is 0.001 rather than 0.0001. Our final constraints for the model are given in the below table.

Table: All the values considered for the model.
Coming to pre-processing of data the labels like digit 2,5,9,... All will be converted to one-hot-encoding which means in that row only the index of digit will be 1 and all others zero. To include the input of the inner layer from the outer layer use the matrix multiplication of all the outer layers to the weights between them and the inner layer. Initial weights and bias are taken from a truncated normal distribution with a standard deviation of 0.01 and here we are using bias because it shifts the activation function. We are using Adam Optimizer and for the loss function, I am using SoftMax cross-entropy function.
Results of Classification of Digits:-

Table: The table shows the accuracy of 25 epochs.
The accuracy of the testing dataset is 0.9723 or 97.23%.
The confusion matrix of the classification of the digits is shown below.


Table: The table shows the True Positive, True Negative





Comments
Post a Comment